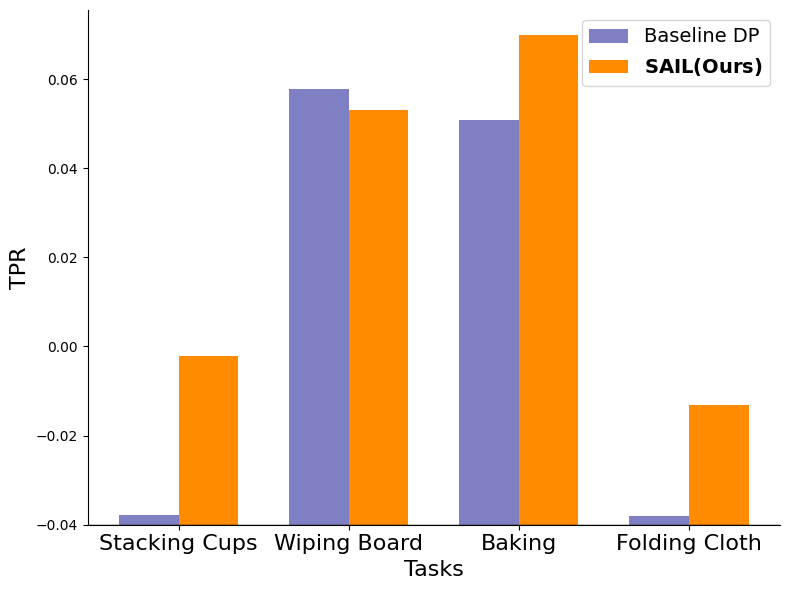
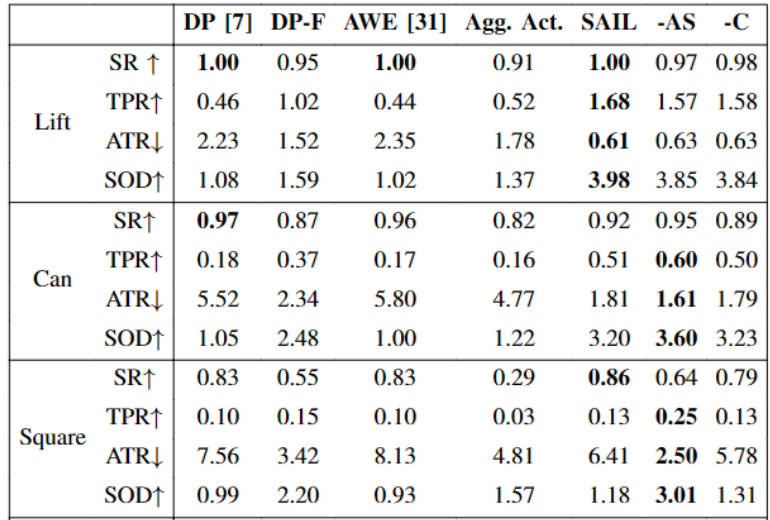
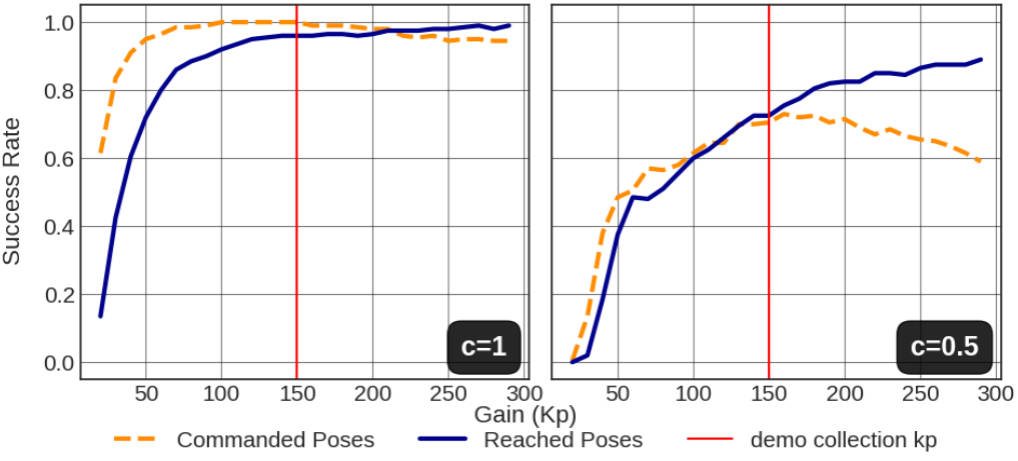
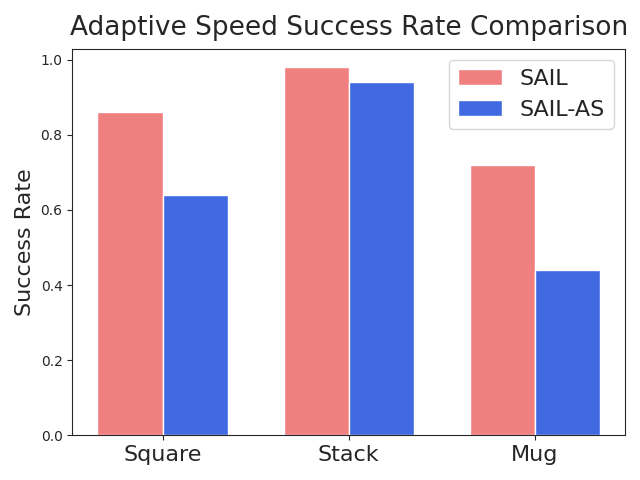
Offline Imitation Learning (IL) methods such as Behavior Cloning (BC)
are effective at acquiring complex robotic manipulation skills.
However, existing IL-trained policies are confined to execute the
task at the same speed as shown in the demonstration. This limits
the task throughput of a robotic system, a critical requirement
for applications such as industrial automation. In this paper, we introduce
and formalize the novel problem of enabling faster-than-demonstration execution
of visuomotor policies and identify fundamental challenges in robot dynamics
and state-action distribution shifts. We instantiate the key insights as
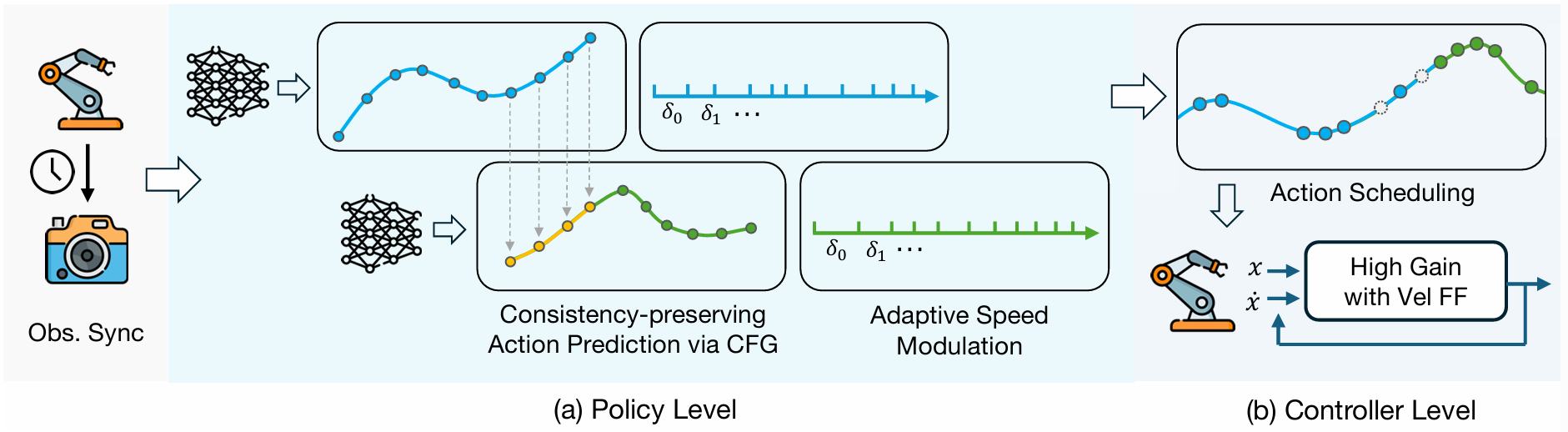
SAIL (Speed-Adaptive Imitation Learning), a full-stack system
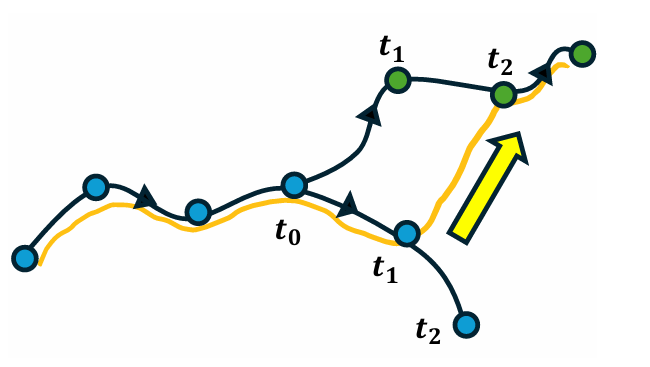
integrating four tightly-connected components: (1) a consistency-preserving
action inference algorithm for smooth motion at high speed, (2) high-fidelity
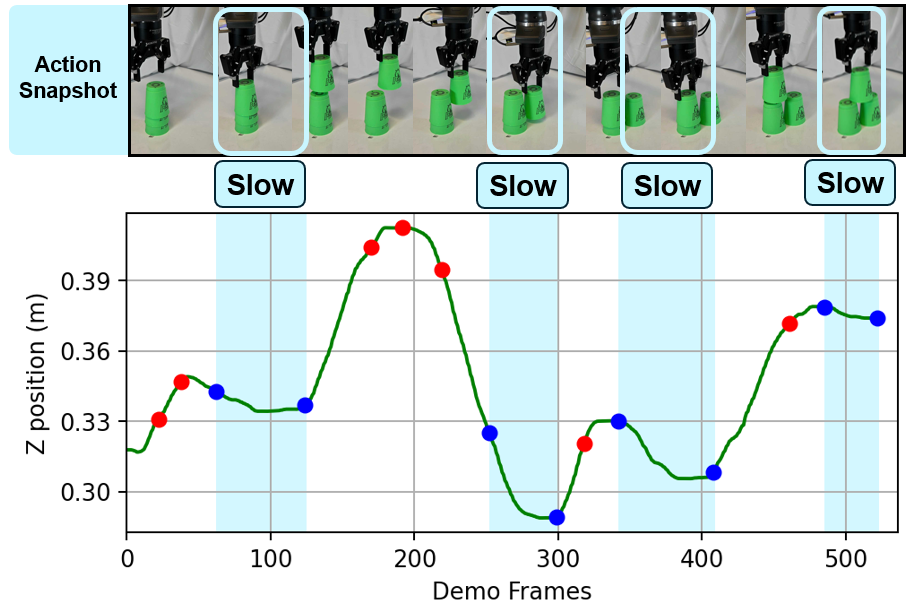
tracking of controller-invariant motion target, (3) adaptive speed modulation
that dynamically adjusts execution speed based on motion complexity, and (4)
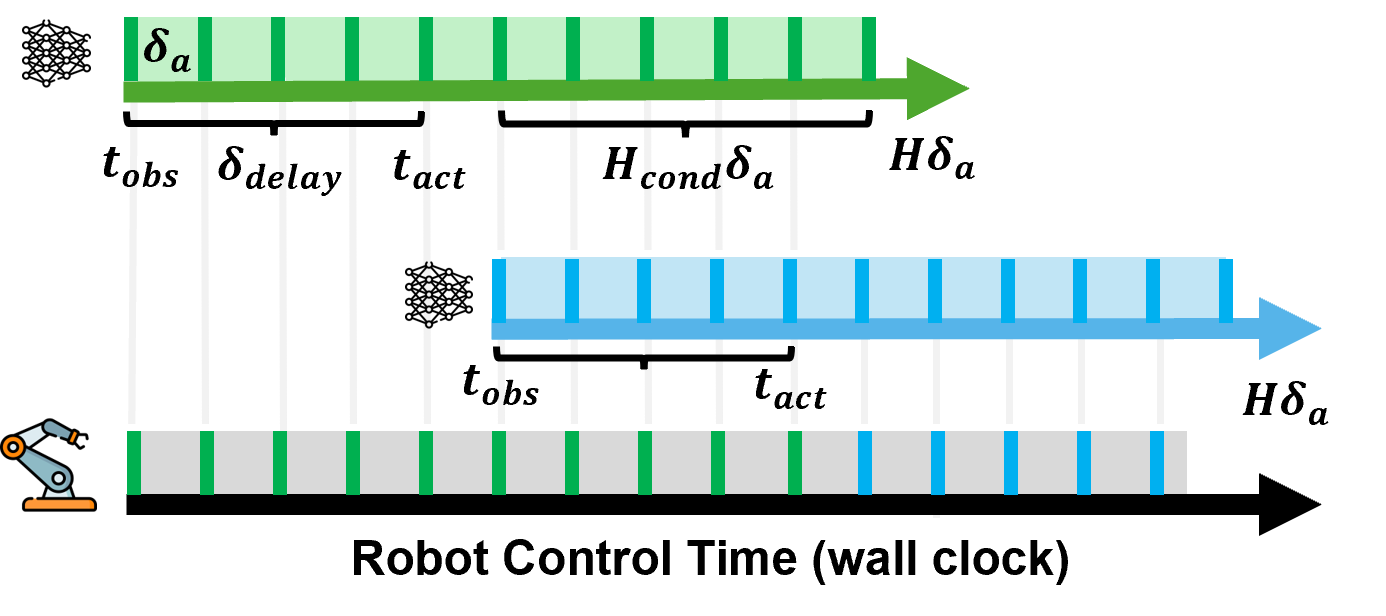
action scheduling to handle real-world system latencies. Experiments in 12 tasks
across simulation and two real robot platforms shows that SAIL achieves up to
a 4× speedup over demonstration speed in simulation and
up to 3.2× speedup on physical robots.